1 索引概念
索引用于快速查找在某个列中某个特定值的行,不使用索引,数据库必须从第1条记录开始读完整个表,知道找出需要的行。表越大,查询数据所花费的时间越多。如果表中查询的列有索引,数据库能快速到达一个位置去查找数据,而不必遍历所有数据。
索引是一个单独的、存储在磁盘上的数据库结构,包含对数据表里所有记录的引用指针。使用索引用于快速找出一个或多个列中有特定值的行,对相关列使用索引是降低查询操作时间的最佳途径。索引包含由表或试图中的一列或多列生成的键。
索引的优点:
◊ 通过创建唯一索引,可以保证数据库表中每一行数据的唯一性。
◊ 可以大大加快数据的查询速度,这也是创建索引的最主要的原因。
◊ 实现数据的参照完整性,可以加速表和表之间的连接。
◊ 在使用分组和排序子句进行数据查询时,可以显著减少查询中分组和排序的时间。
索引的缺点:
◊ 创建索引和维护索引需要耗费时间,并且随着数据量的增加所消耗的时间会增加。
◊ 索引需要占用磁盘空间,除了数据表占数据空间之外,每一个索引还要占用一定的物理空间。如果有大量的索引,索引文件可能比数据文件更快达到最大文件大小。
◊ 当对表中的数据进行添加、修改和删除的时候,索引需要动态维护,这样降低了数据的维护速度。
2 索引的分类
SQL Server中索引有两种:聚集索引和非聚集索引。它们的区别是在物理数据的存储方式上。
2.1 聚集索引
聚集索引基于数据行的键值,在表内排序和存储这些数据行。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。
创建聚集索引时需要考虑的几个因素:
◊ 每个表只能有一个聚集索引
◊ 表中的物理顺序和索引中行的物理顺序是相同的,创建任何非聚集索引之前要首先创建聚集索引,这是因为聚集索引改变了表中行的物理顺序。
◊ 关键值的唯一性使用UNIQUE关键字或者由内部的唯一标识符明确维护。
◊ 在索引的创建过程中,SQL Server临时使用当前数据库的磁盘空间,所以要保证有足够的空间创建聚集索引。
2.2 非聚集索引
非聚集索引具有完全独立于数据行的结构,使用非聚集索引不用将物理数据页的数据按列排序。非聚集索引包含索引键值和指向表数据存储位置的行定位器。
可以对表或索引视图创建多个非聚集索引。设计非聚集索引是为了改善经常使用的、没有建立聚集索引的查询的性能。
查询优化器在查找数据值时,先查找非聚集索引以找到数据值在表中的位置,然后直接从该位置检索数据。这使得非聚集索引成为完全匹配查询的最佳选择,因为索引中包含所查找的数据值在表中的精确位置的项。
考虑使用非聚集索引的查询情况:
◊ 使用JOIN或GROUP BY子句。应为连接和分组操作中所涉及的列创建多个非聚集索引,为任何外键列创建聚集索引。
◊ 包含大量唯一值的字段。
◊ 不返回大型结果集的查询。创建筛选索引以覆盖从大型表中返回定义完善的行子集的查询。
◊ 经常包含在查询的搜索条件中的列。
3 创建索引
SQL Server中创建索引的两中方法:在SQL Server Management Studio的对象资源管理器中,通过图形化工具创建或使用T-SQL语句创建。
3.1 使用SQL Server Management Studio对象资源管理器创建
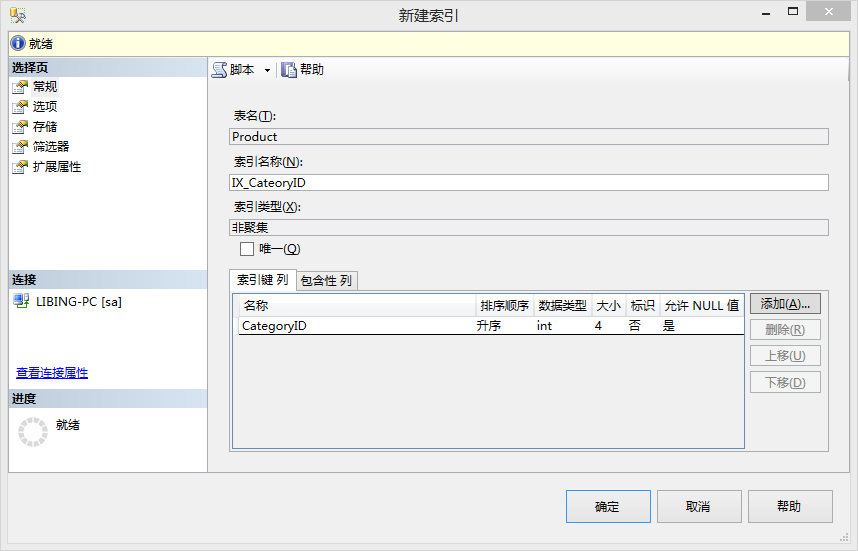
◊ 在【对象资源管理器】中,展开【数据库】找到需要创建索引的数据表节点,展开该节点下的子节点,右击【索引】节点,在弹出的快捷菜单中选择【新建索引】->【非聚集索引】。

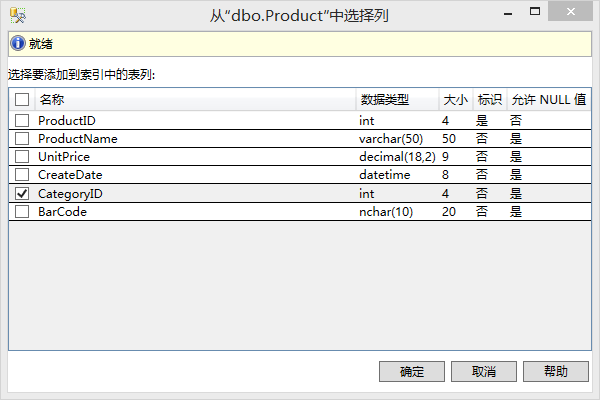
◊ 在打开的【新建索引】界面选择需要创建索引的列,进而创建索引。
3.2 T-SQL创建索引
CREATE INDEX语法:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON
创建索引:
IF EXISTS (SELECT name from sys.indexes WHERE name = N'IX_Product_CategoryID') DROP INDEX IX_Product_CategoryID ON [dbo].[Product];GOCREATE NONCLUSTERED INDEX IX_Product_CategoryID ON [dbo].[Product]([CategoryID]);
创建过滤索引:
CREATE NONCLUSTERED INDEX IX_Product_CategoryID ON [dbo].[Product]([CategoryID])WHERE [UnitPrice] > 10
4 查看表或试图的索引信息
系统存储过程sp_helpindex可以返回某个表或试图的索引信息。
语法:
sp_helpindex [ @objname = ] 'name'
查看表中包含的全部索引:
EXEC sp_helpindex N'Product'
5 查看索引的统计信息
索引的统计信息可以用来分析索引性能,更好地维护索引。
DBCC SHOW_STATISTICS (N'Portal.dbo.Product', N'IX_CategoryID')
6 重命名索引
系统存储过程sp_rename可以用于更改索引的名称,其语法格式如下:
sp_rename [ @objname = ] 'object_name' , [ @newname = ] 'new_name' [ , [ @objtype = ] 'object_type' ]
示例:
EXEC sp_rename 'dbo.Product.IX_CategoryID' , 'IX_Product_CategoryID' , 'INDEX'
7 修改索引
7.1 ALTER INDEX语法
ALTER INDEX { index_name | ALL } ON 7.2 示例
禁用索引
ALTER INDEX [IX_CategoryID] ON [dbo].[Product] DISABLE
重新启用索引
ALTER INDEX [IX_CategoryID] ON [dbo].[Product] REBUILD
8 删除索引
DROP INDEX语法:
DROP INDEX{ [ ,...n ] | [ ,...n ]} ::= index_name ON 示例:
DROP INDEX [dbo].[Product].[IX_Product_CategoryID]
DROP INDEX [IX_Product_CategoryID] ON [dbo].[Product]